OVN Recon: Making OpenShift Networking Connections
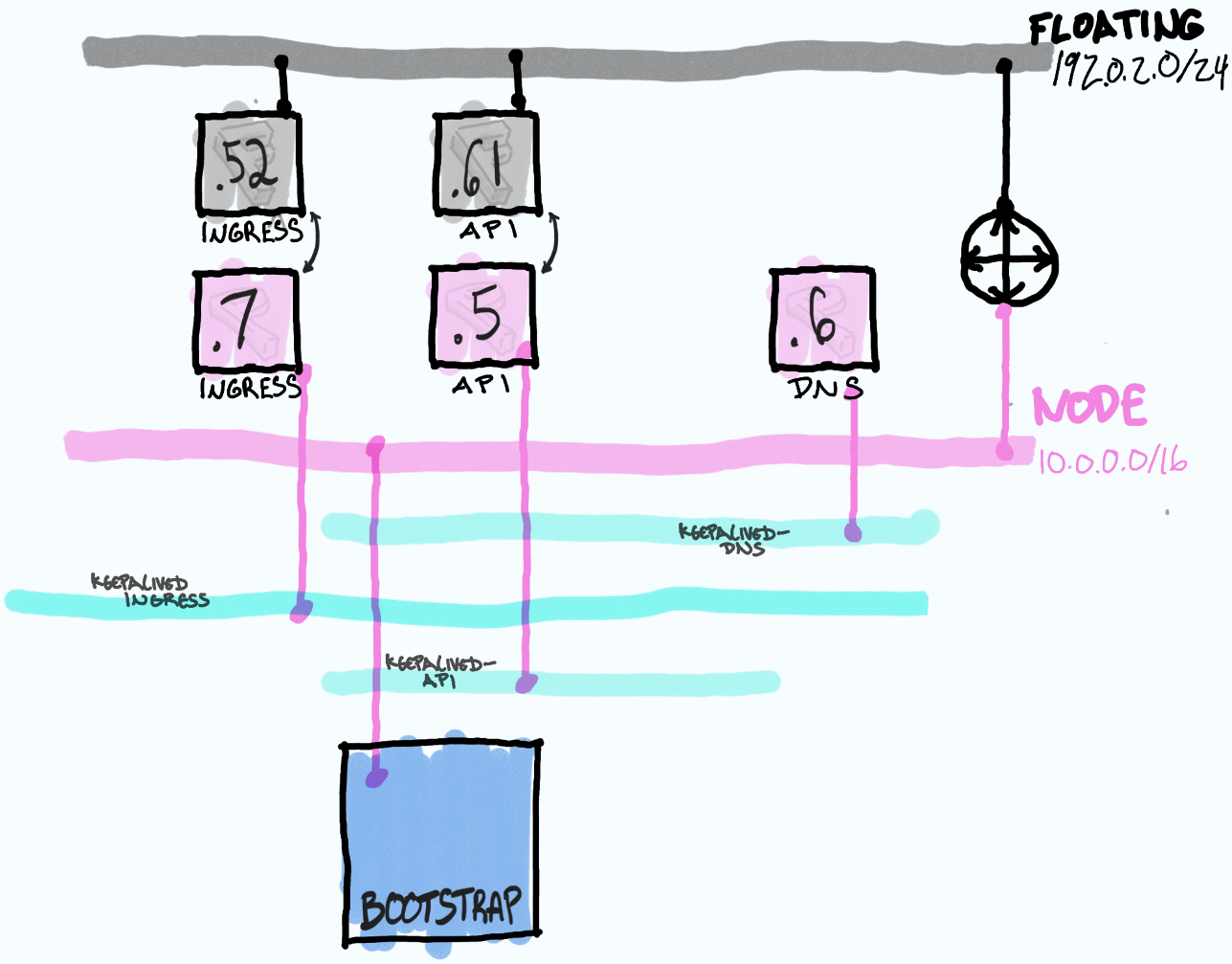
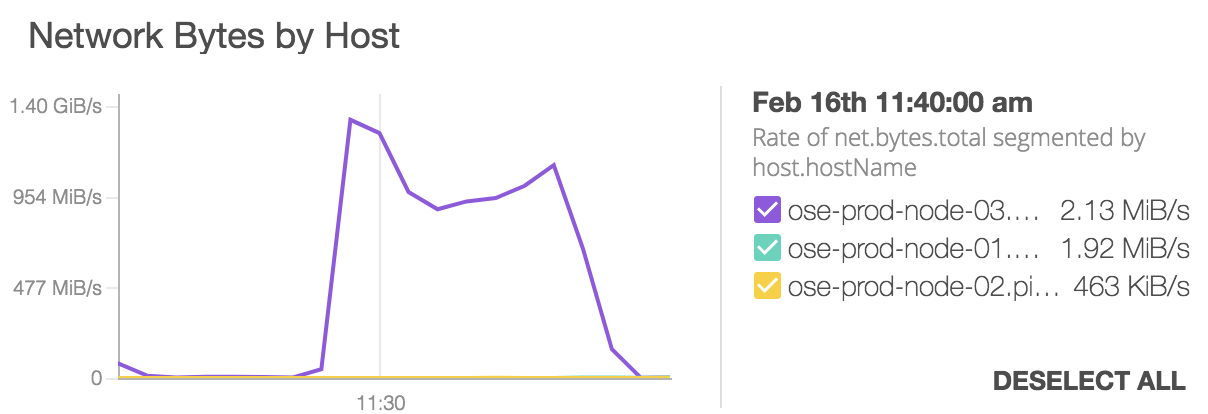
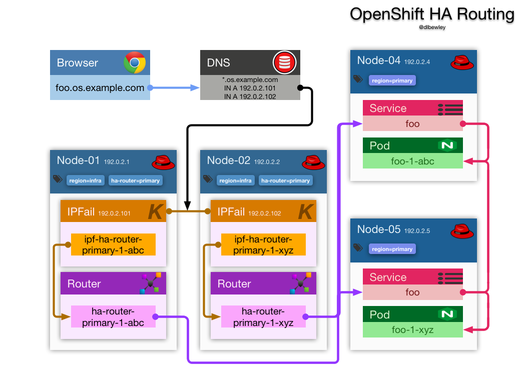
The OpenShift networking stack, including the OVN-Kubernetes CNI, Cluster Network Operator, NMState operator, and FRR-K8s is very flexible, but it may not always be obvious how the pieces fit together to form a solution.
OVN Recon is an OpenShift Console plugin built to make the connections that help develop your mental model for understanding OpenShift networking.