Upgrading OpenShift Enterprise from 3.1 to 3.2
Upgrading from OSE 3.1 to 3.2 using the playbook went quite well for me, but there were a few issues to sort out.
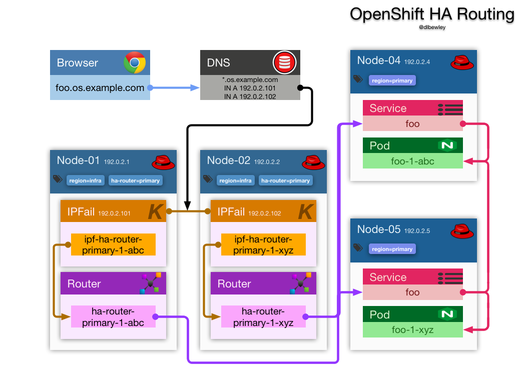
The issues were related to:
- ip failover had to be updated manually
- there was about 5 minutes downtime during the upgrade
- updates to image streams
- docker error messages
- updated policy and role bindings build strategy Source is not allowed
- hawkular metrics
Upgrade Process
Following the directions is pretty straight forward.