February 16, 2018
OpenShift HA Routing uses haproxy application routers to get traffic into the cluster. These application routers are made redundant by running ipfailover (keepalived) pods to maintain a set of Virtual IPs on each infrastructure node where the application routers run. These VIPs are then referenced by round robin DNS records to enable a measure of load balancing.
OK, so now you are load balancing at the network layer, but what about the link layer? Did you know that even if you somehow manage to perfectly balance traffic among the VIPs using RR DNS you could still be using only one of your application routers? Well you could be!
Example Environment
Here is an environment with 3 infrastructure nodes and and 3 primary or applications nodes in the 192.0.2.0/24 address space. The application domain is os.example.com.
The 3 infrastucture nodes participate in the HA routing by running ipfailover pods that implement keepalived to keep IPs 192.0.2.101-103 alive. Along side those ipfailover pods an haproxy pod binds to each IP.
The DNS response for lookups in *.os.example.com will look like this. The order of the addresses in the response should be varied by the DNS server.
$ dig +short foo.os.example.com
192.0.2.103
192.0.2.101
192.0.2.102
Now looking deeper into the network interface on the nodes, let’s enumerate the MAC address and the IP addresses on eth0:
- Infra Node 1
[root@ose-prod-node-01 ~]# ethtool -P eth0
Permanent address: 00:1a:4a:48:BE:4B
[root@ose-prod-node-01 ~]# ip -4 -o a show eth0
2: eth0 inet 192.0.2.1/24 brd 192.0.2.255 scope global dynamic eth0\ valid_lft 62345sec preferred_lft 62345sec
2: eth0 inet 192.0.2.102/32 scope global eth0\ valid_lft forever preferred_lft forever
2: eth0 inet 192.0.2.101/32 scope global eth0\ valid_lft forever preferred_lft forever
2: eth0 inet 192.0.2.103/32 scope global eth0\ valid_lft forever preferred_lft forever
- Infra Node 2
[root@ose-prod-node-02 ~]# ethtool -P eth0
Permanent address: 00:1a:4a:48:BE:EF
[root@ose-prod-node-02 ~]# ip -4 -o a show eth0
2: eth0 inet 192.0.2.2/24 brd 192.0.2.255 scope global dynamic eth0\ valid_lft 72864sec preferred_lft 72864sec
2: eth0 inet 192.0.2.103/32 scope global eth0\ valid_lft forever preferred_lft forever
2: eth0 inet 192.0.2.101/32 scope global eth0\ valid_lft forever preferred_lft forever
2: eth0 inet 192.0.2.102/32 scope global eth0\ valid_lft forever preferred_lft forever
- Infra Node 3
[root@ose-prod-node-03 ~]# ethtool -P eth0
Permanent address: 00:1a:4a:48:BE:4C
[root@ose-prod-node-03 ~]# ip -4 -o a show eth0
2: eth0 inet 192.0.2.3/24 brd 192.0.2.255 scope global dynamic eth0\ valid_lft 81509sec preferred_lft 81509sec
2: eth0 inet 192.0.2.101/32 scope global eth0\ valid_lft forever preferred_lft forever
2: eth0 inet 192.0.2.102/32 scope global eth0\ valid_lft forever preferred_lft forever
2: eth0 inet 192.0.2.103/32 scope global eth0\ valid_lft forever preferred_lft forever
Node Summary
| Node | Eth0 MAC | Eth0 IPs |
|---|---|---|
| ose-prod-node-01 | 00:1a:4a:48:BE:4B | 192.0.2.1, 192.0.2.101, 192.0.2.102, 192.0.2.103 |
| ose-prod-node-02 | 00:1a:4a:48:BE:EF | 192.0.2.2, 192.0.2.101, 192.0.2.102, 192.0.2.103 |
| ose-prod-node-03 | 00:1a:4a:48:BE:4C | 192.0.2.3, 192.0.2.101, 192.0.2.102, 192.0.2.103 |
Client Traffic
Web browsers will look up the IP address for app.os.example.com and will get back three A records (192.0.2.101, 192.0.2.102, 192.0.2.103) in the response.
The DNS server will shuffle the order of the IPs in the response and the client will typically choose the first IP in the list to connect to.
All three of these IPs are always available even if only one node is alive and the client has no idea which node is serving its traffic.
Keep in mind it is the network router attached to the nodes that will decide how to relay the packet from the client to those 3 IP addresses. Also remember that ultimately the packet will be sent to a MAC address, not an IP address. How? Adress resolution protocol. Since the router is on the same layer 2 segment as these VIPs it will maintain a ARP table that maps IP addresses to MAC addresses. Over time, or after some event like a network split or node reboots the ARP table could wind up thwarting your efforts to balance the traffic.
Network Router
Let’s check the ARP table on the router to see where traffic will be sent at the link layer.
core(s1)# sh ip arp 192.0.2.101
Address Age (min) Hardware Addr Interface
192.0.2.101 0 001a.4a48.BE4B Vlan176, Port-Channel391
core(s1)# sh ip arp 192.0.2.102
Address Age (min) Hardware Addr Interface
192.0.2.102 0 001a.4a48.BE4C Vlan176, Port-Channel391
core(s1)# sh ip arp 192.0.2.103
Address Age (min) Hardware Addr Interface
192.0.2.103 0 001a.4a48.BE4C Vlan176, Port-Channel391
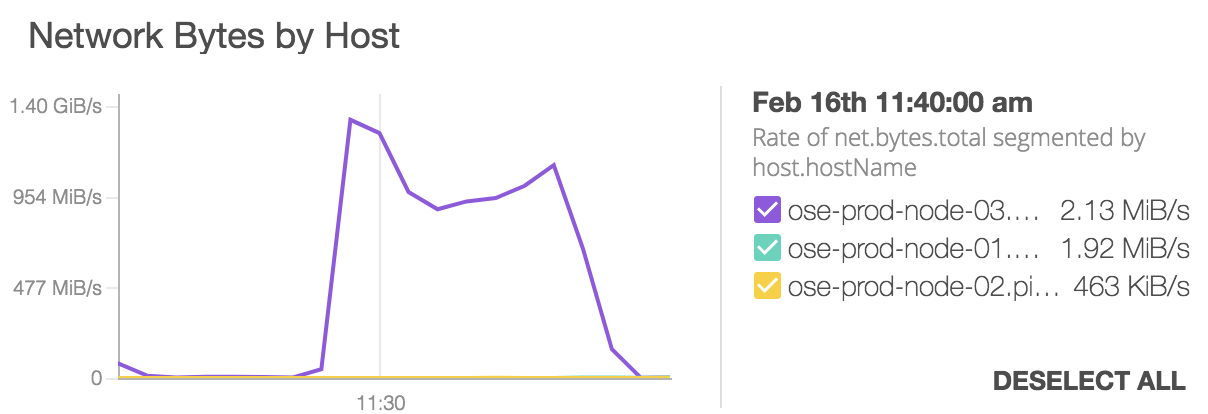
You can see that IP address 192.0.2.101 is known to the router by MAC (Hardware) address 001a.4a48.BE4B which is eth0 on Node 1.
However, both addresses 192.0.2.102 and 192.0.2.103 are known to the router by the same MAC address 001a.4a48.BE4C with is eth0 on Node 3.
Router Summary
| Router ARP Table | IP | MAC Address |
|---|---|---|
| 192.0.2.101 | 00:1a:4a:48:BE:4B | |
| 192.0.2.102 | 00:1a:4a:48:BE:4C | |
| 192.0.2.103 | 00:1a:4a:48:BE:4C |
This means that any time the network router is sending traffic to those 3 IPs it will always send it nodes 1 and 3. Node 2 will never get any traffic for those VIPs. Things could likely be worse. You might have all 3 IPs associated with the same IP address. Go look now!
The Fix
So how do you fix that? GARP. A gratuitous ARP from the node can inform the router, “Hey! I am MAC X:X and I answer to IP Y.Y. Remember that!” and the router will do as it is told and update it’s ARP table.
ssh root@ose-prod-node-01 arping -c 4 -A -I eth0 192.0.2.101
ssh root@ose-prod-node-02 arping -c 4 -A -I eth0 192.0.2.102
ssh root@ose-prod-node-03 arping -c 4 -A -I eth0 192.0.2.103
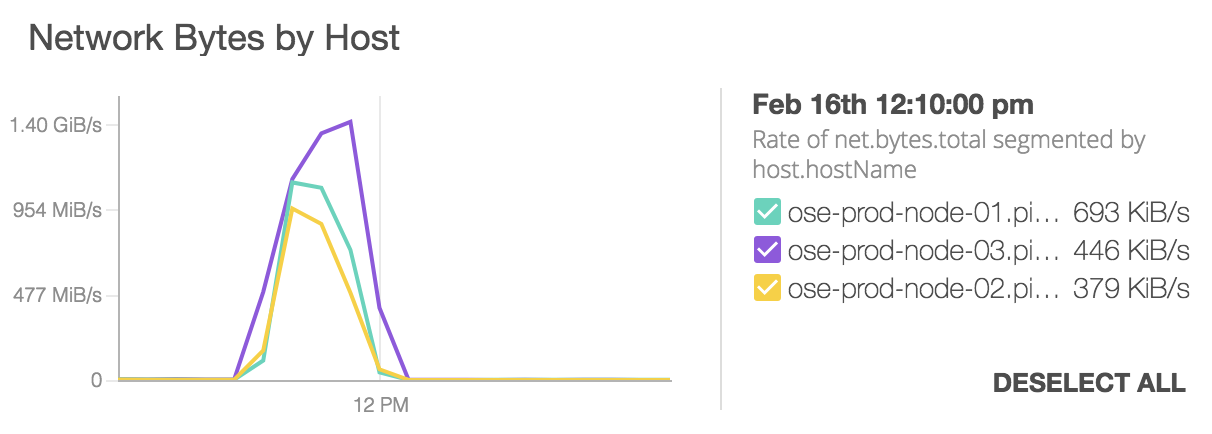
The Caveat
Of course if one of the nodes were to reboot it’s MAC address would become unreachable, it would fall out of the router ARP table, the router would send an ARP request and another MAC address would fill in and do double duty. Things will stay like that indefinitely.
One approach would be to perform the above arping on a regular basis or after maintenance events that take down infrastructure nodes.
Mind the GARP!