March 1, 2016
Highly availabile containers in OpenShift are baked into the cake thanks to replication controllers and service load balancing, but there are plenty of other single points of failure. Here is how to eliminate many of those.
Single Points of Failure
The components of OpenShift include:
- Master controller manager server and API endpoint
- Etcd configuration and state storage
- Docker Registry
- Router haproxy
This post is mostly about adding high availability to the routing layer.
OpenShift High Availability Configuration
What do we have to do?
Overview
- Put together the inventory and install with
openshift_master_cluster_method=native - Do the basic configuration with a single router to point DNS to a router
- Setup the HA router with IP failover and replace the standard router
- Update DNS to use IP failover and update DNS to use the floating IP
Host Inventory and Installation
Of course you’ll be doing advanced install which leverages the OpenShift Ansible playbook.
An example installation might look like this:
- 3 master nodes
- 2 infrastructure nodes
- 3 primary nodes
- 3 etcd servers
- 2 load balancers
Here is an overview of the hosts with IP addresses and labels.
Infrastructure Nodes
The infrastructure nodes will be used to run non-user pods, like haproxy routers.
| Name | IP | Labels |
|---|---|---|
| ose-ha-node-01.example.com | 192.0.2.1 | region=infra, zone=metal |
| ose-ha-node-02.example.com | 192.0.2.2 | region=infra, zone=metal |
Primary Nodes
The primary nodes will run user application pods.
| Name | IP | Labels |
|---|---|---|
| ose-ha-node-03.example.com | 192.0.2.3 | region=primary, zone=rhev |
| ose-ha-node-04.example.com | 192.0.2.4 | region=primary, zone=rhev |
| ose-ha-node-05.example.com | 192.0.2.5 | region=primary, zone=rhev |
Master Nodes
The master servers act as the API endpoint and can be load balanced by independent load balancer nodes or a dedicated hardware. One master is elected as the contoller manager server.
| Name | IP | Labels |
|---|---|---|
| ose-ha-master-01.example.com | 192.0.2.21 | region=infra, zone=rhev |
| ose-ha-master-02.example.com | 192.0.2.22 | region=infra, zone=rhev |
| ose-ha-master-03.example.com | 192.0.2.23 | region=infra, zone=rhev |
Load Balancer Servers
These hosts run haproxy and front end the masters using a hostname defined as openshift_master_cluster_hostname=ose-master.os.example.com in the hosts file.
| Name | IP |
|---|---|
| ose-ha-lb-01.example.com | 192.0.2.41 |
| ose-ha-lb-02.example.com | 192.0.2.42 |
Etcd Servers
Etcd is used to maintain all state for the cluster, and is configured as a standalone cluster.
| Name | IP |
|---|---|
| ose-ha-etcd-01.example.com | 192.0.2.31 |
| ose-ha-etcd-02.example.com | 192.0.2.32 |
| ose-ha-etcd-02.example.com | 192.0.2.33 |
Hosts Inventory File
And here is the inventory file based on the examples.
[OSEv3:children]
masters
nodes
etcd
lb
[OSEv3:vars]
ansible_ssh_user=root
debug_level=2
deployment_type=openshift-enterprise
use_cluster_metrics=true
openshift_master_metrics_public_url=https://metrics.os.example.com/hawkular/metrics
openshift_master_identity_providers=[{'name': 'my_ldap_provider', 'challenge': 'true', 'login': 'true', 'kind': 'LDAPPasswordIdentityProvider', 'attributes': {'id': ['dn'], 'email': ['mail'], 'name': ['cn'], 'preferredUsername': ['uid']}, 'bindDN': '', 'bindPassword': '', 'ca': '', 'insecure': 'true', 'url': 'ldap://ldap.example.com:389/ou=people,o=example.com?uid'}]
use_fluentd=true
openshift_master_cluster_method=native
openshift_master_cluster_hostname=master.os.example.com
openshift_master_cluster_public_hostname=master.os.example.com
osm_default_subdomain=os.example.com
osm_default_node_selector='region=primary'
openshift_router_selector='region=infra'
openshift_registry_selector='region=infra'
[masters]
ose-ha-master-[01:03].example.com
[etcd]
ose-ha-etcd-[01:03].example.com
[lb]
ose-ha-lb-01.example.com
ose-ha-lb-02.example.com
[nodes]
ose-ha-master-[01:03].example.com openshift_node_labels="{'region': 'infra', 'zone': 'rhev'}" openshift_schedulable=False
ose-ha-node-[01:02].example.com openshift_node_labels="{'region': 'infra', 'zone': 'metal'}"
ose-ha-node-[03:05].example.com openshift_node_labels="{'region': 'primary', 'zone': 'rhev'}"
Perform the Install
Run my prep playbook and then run the byo playbook to perform the actual install.
Configuration
Initial DNS Configuration
Access to applications like app-namespace.os.example.com starts with a wildcard DNS A record in your domain, *.os.example.com pointing to a router pod. The router pod should be assigned to an infrastructure node since the container will be using the host port to attach ha-proxy to.
The DNS records should point to the router pods which are using the infrastructure node host ports. That means the DNS record should point to the IP of the infrastructure node(s). But what if that node fails? Don’t worry about that just yet.
Using nsupdate and a key which is allowed to manipulate our os.example.com zone, let’s insert a * wildcard, and point the name ose-master at the IP of the first load balancer node (for now).
nsupdate -v -k os.example.com.key
update add *.os.example.com 300 A 192.0.2.1
update add master.os.example.com 300 A 192.0.2.41
send
quit
HA Routing
Of course if DNS points at the IP of a single node, your apps will become unavailable if that node reboots. That can be fixed with a IP Failover service and floating IPs.
The result will look like this:
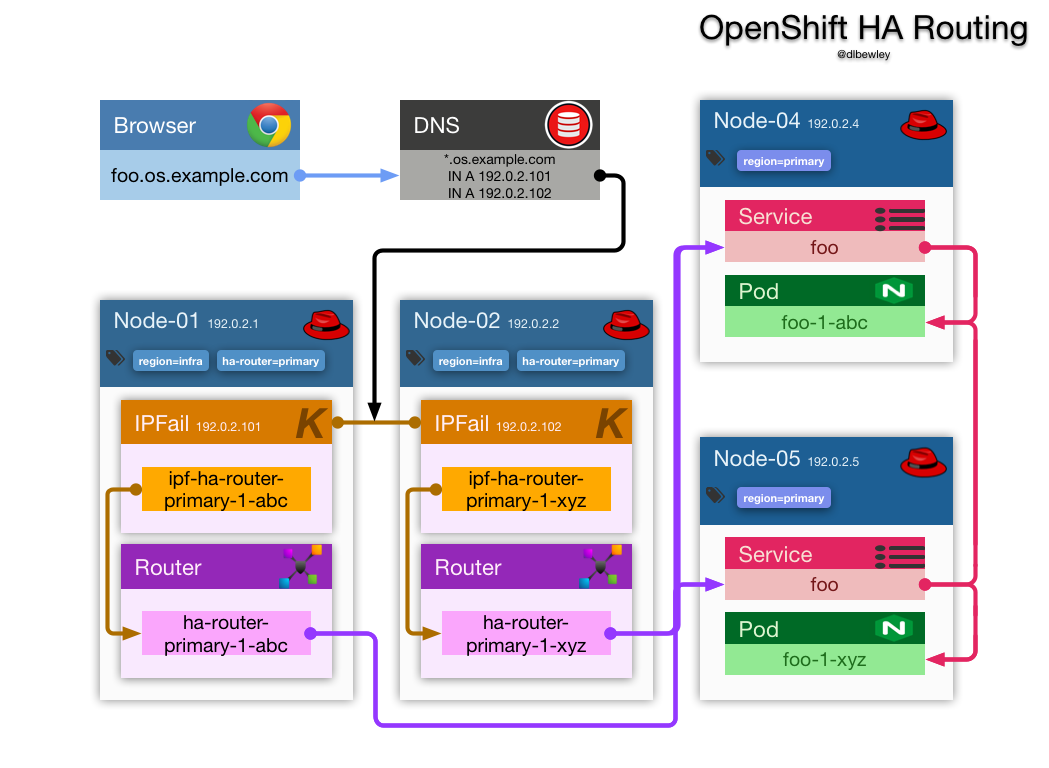
Create a HA router set for the application pods in the primary region. The routers will run on the schedulable nodes in the infra region.
OpenShift’s ipfailover internally uses keepalived, so ensure that multicast is enabled on the labeled nodes, specifically the VRRP multicast IP address 224.0.0.18.
Label the nodes ha-router=primary so they can be selected for the service
oc label nodes ose-ha-node-0{1,2} "ha-router=primary"
# confirm the change
oc get nodes --selector='ha-router=primary'
NAME LABELS STATUS AGE
ose-ha-node-01.example.com ha-router=primary,kubernetes.io/hostname=ose-ha-node-01.example.com,region=infra,zone=rhev Ready 3d
ose-ha-node-02.example.com ha-router=primary,kubernetes.io/hostname=ose-ha-node-02.example.com,region=infra,zone=rhev Ready 3d
Infrastructure Nodes
| Name | IP | Labels |
|---|---|---|
| ose-ha-node-01.example.com | 192.0.2.1 | region=infra, zone=metal, ha-router=primary |
| ose-ha-node-02.example.com | 192.0.2.2 | region=infra, zone=metal, ha-router=primary |
Use router service account (or optionally create ipfailover account) to create the router. Check that it exists.
oc get scc privileged -o json | jq .users
[
"system:serviceaccount:default:registry",
"system:serviceaccount:default:router",
"system:serviceaccount:openshift-infra:build-controller"
]
Since we have 2 Infrastructure (region=infra) nodes which are labeled ha-router=primary let’s start 2 replicas of a router called ha-router-primary.
Go get a legit wildcard cert for *.os.example.com instead of generating one, and concatenate the cert, key, and intermediate certs into a pem file.
cat \
wildcard.os.example.com.crt \
wildcard.os.example.com.key \
gd_bundle-g2-g1.crt \
> router_wildcard.os.example.com.pem
Deploy the router with the wildcard cert as the default certificate.
oadm router ha-router-primary \
--replicas=2 \
--selector="ha-router=primary" \
--selector="region=infra" \
--labels="ha-router=primary" \
--credentials=/etc/origin/master/openshift-router.kubeconfig \
--default-cert=router_wildcard.os.example.com.pem \
--service-account=router
password for stats user admin has been set to cixBqxbXyz
DeploymentConfig "ha-router-primary" created
Service "ha-router-primary" created
Edit the deployment config for the HA router and add the default cert within spec.containers.env.name[DEFAULT_CERTIFICATE]
oc edit dc ha-router-primary
From the initial install, there will be a pre-existing router (router-1) holding the host ports (80,443) which precludes starting the ha router instances. Scale that old router down to 0 pods:
oc scale --replicas=0 rc router-1
Pick 2 IP addresses which will float between the 2 infra nodes and create a IP failover service.
IP Failover Nodes
| IP Failover Service | IPs | Labels |
|---|---|---|
| ipf-ha-router-primary | 192.0.2.101, 192.0.2.102 | ha-router=primary |
Create a IP failover configuration named ipf-ha-router-primary having N replicas equal to number nodes labeled ha-router=primary
oadm ipfailover ipf-ha-router-primary \
--replicas=2 \
--watch-port=80 \
--selector="ha-router=primary" \
--virtual-ips="192.0.2.101-102" \
--credentials=/etc/origin/master/openshift-router.kubeconfig \
--service-account=router \
--create
Keepalived Readiness Probe
As of OSE 3.2 the oc status -v command will warn you that there is no readiness probe defined for this ipf-ha-router-primary deployment config. I tried to resolve that warning with this probe, but deployment failed with a connection refused to port 1985 on the node host IP.
oc set probe dc/ipf-ha-router-primary --readiness --open-tcp=1985
OpenShift HA DNS Configuration
Wildcard DNS records point users to the OpenShift routers providing ingress to application services.
Update the DNS wildcard records to reflect the floating IPs instead of the infra nodes’ primary IPs.
nsupdate -v -k os.example.com.key
update delete *.os.example.com 300 A 192.0.2.1
update add *.os.example.com 300 A 192.0.2.101
update delete *.os.example.com 300 A 192.0.2.2
update add *.os.example.com 300 A 192.0.2.102
send
quit
HA Master
TODO
If a lb group is defined in the Ansible playbook inventory then a haproxy node will be setup to load balance the master API endpoint. The load balancer becomes a single point of failure, however.
HA Registry
TODO
This is pretty easy. I’ll post about it at some point.
Related Documentation
- OpenShift Router Concept
- OpenShift Router Deployment
- OpenShift Highly Available Router
- Load Balance of non-HTTP is not yet available beyond node ports and ipfailover